

Machine learning is everywhere - powering tools like Netflix recommendations and Gmail spam filters. Want to build your first model? Here's what you'll learn:
- Prepare Your Data: Choose datasets, clean them, and split into training/testing sets.
- Understand ML Basics: Learn about supervised, unsupervised, and reinforcement learning.
- Train a Model: Use Python and scikit-learn to apply algorithms like linear regression or decision trees.
- Evaluate & Improve: Measure accuracy, precision, and recall. Fix overfitting and underfitting.
1: Understanding Machine Learning Basics
Types of Machine Learning
Machine learning can be categorized into three main types, each with its own approach to learning:
- Supervised Learning: This method uses labeled data to train models. For example, Gmail learns to identify spam by analyzing emails marked as spam by users.
- Unsupervised Learning: Here, the model identifies patterns in unlabeled data. Think of it as grouping customers based on their shopping habits without any predefined categories.
- Reinforcement Learning: This involves learning through trial and error. The model is rewarded for correct actions and penalized for mistakes, much like training a pet.
If you're just starting out, supervised learning is the best place to begin. It provides clear feedback, is straightforward to grasp, and forms the basis for more advanced techniques.
Key Parts of an ML Model
Every machine learning model is built around three essential components:
- Datasets: These are the raw materials for training and testing your model. Clean, consistent, and representative data is critical to ensure the model performs well.
- Algorithms: These are the methods the model uses to find patterns in the data.
- Evaluation Metrics: These tools measure how accurate and effective the model is.
Quality data plays a huge role in the success of your model. Poor data can lead to overfitting (where the model memorizes the training data) or underfitting (where the model fails to identify important patterns). Treat your data like the foundation of a house - it needs to be solid for the rest of the system to work.
In the next section, we’ll explore how to prepare your dataset, the first step in building a reliable machine learning model.
Related video from YouTube
2: Preparing Your Dataset
Getting your dataset ready is a key step in building a machine learning model. Let’s break down how to choose, clean, and split your data to set a strong foundation.
Choosing a Dataset
If you’re just starting out, go for simple and well-documented datasets. Popular choices include the Iris Dataset (for classification tasks) and the Titanic Dataset (for binary classification). Platforms like Kaggle and the UCI Machine Learning Repository are great places to find these.
Cleaning and Preprocessing Data
Raw data is rarely perfect. You’ll need to clean and prepare it using tools like Pandas and Scikit-learn. Here are some key steps:
Handling Missing Values
Missing data can throw off your model. Here’s how to deal with it:
- Fill gaps in numerical data using the mean or median, or remove rows with missing values if you have enough data left.
- For more complex cases, use predictive modeling to estimate missing values.
Feature Normalization
Features often have different scales, which can skew results. Normalize them so they contribute equally to the model. Here’s a quick overview:
| Technique | When to Use | Example |
|---|---|---|
| Min-Max Scaling | When you need values in a 0-1 range | Scaling ages from 0-100 to 0-1 |
| Standardization | To center data around 0 with unit variance | Adjusting to a normal distribution |
| Log Transformation | For reducing skew in exponential data | Converting exponential growth data |
Splitting Data into Training and Testing Sets
Use Scikit-learn’s train_test_split function to divide your data. A common split is 80% for training and 20% for testing. This ensures your model is evaluated on unseen data, giving a better sense of its real-world performance.
3: Building and Training Your Model
Now that your dataset is ready, it's time to create and train your first machine learning model using Python and scikit-learn.
Choosing an Algorithm
The next step is selecting the right algorithm for your task. For example, linear regression works well for predicting continuous values like house prices, while decision trees are great for classification tasks, such as analyzing customer behavior.
| Algorithm | Use Case | Advantages |
|---|---|---|
| Linear Regression | Predicting continuous outcomes | Easy to understand, quick to train, shows clear relationships |
| Decision Trees | Solving classification problems | Intuitive visual flow, handles varied data types, no scaling required |
Implementing with Scikit-Learn
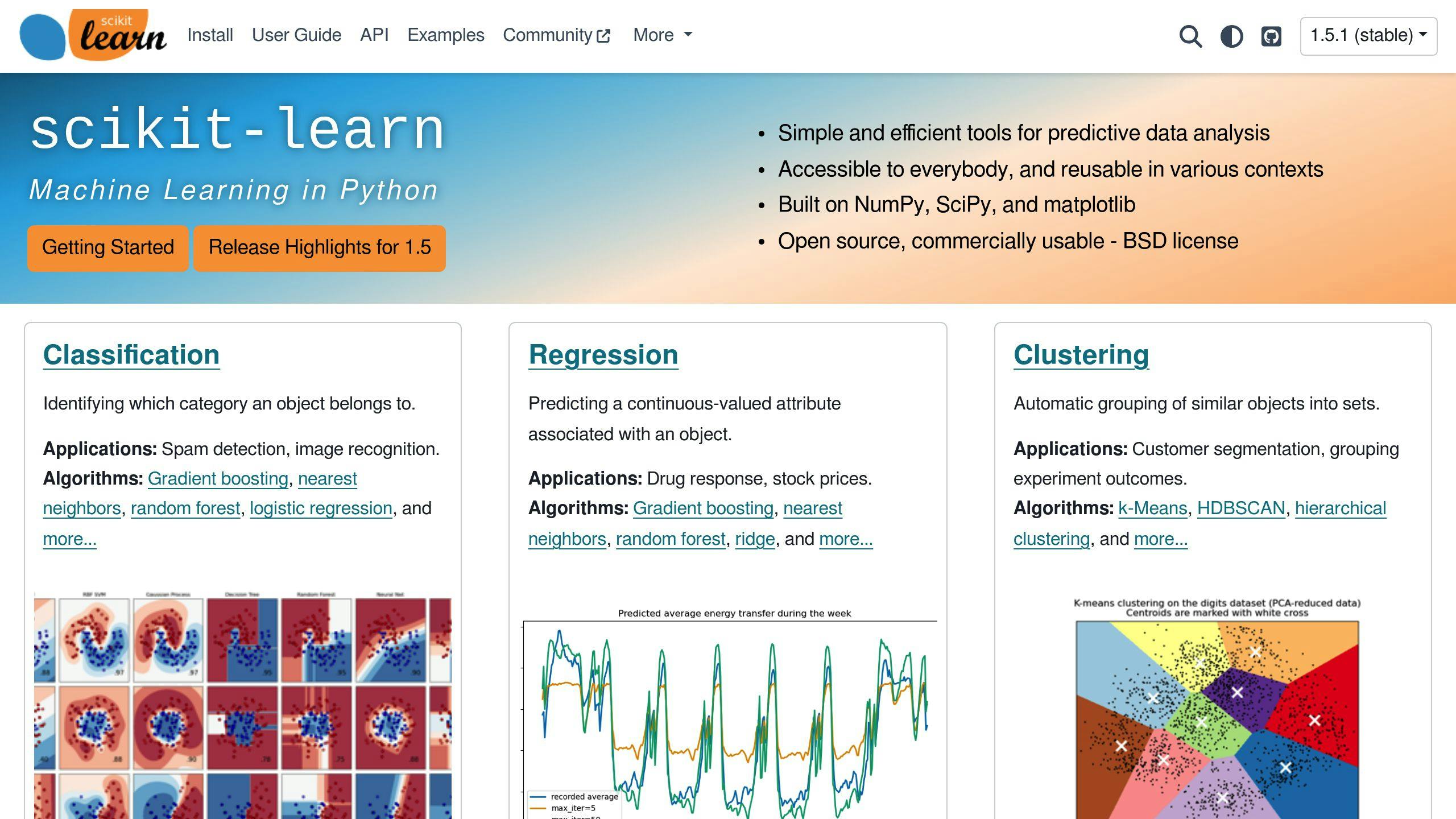
Scikit-learn makes it easy to implement machine learning models. Here's how to set up a simple linear regression model:
# Import libraries
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
# Initialize the model
model = LinearRegression()
One of the best parts of scikit-learn is its consistent workflow across models: you use fit() to train, predict() to make predictions, and score() to evaluate. Once your model is set up, you can move on to training it.
Training the Model
Training your model involves fitting it to your dataset and generating predictions:
# Train the model on your data
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
It's tempting to dive into complex models right away, but simpler algorithms like linear regression are often just as effective and much easier to debug. They also train quickly, making them perfect for beginners. Starting with default settings allows you to focus on understanding the process without getting overwhelmed.
When you train the model, it adjusts its internal parameters to better match the data. This step sets the foundation for evaluating and improving your model later.
4: Evaluating and Improving Your Model
Once your model is trained, the next step is to check how well it performs and make adjustments to improve its results.
Assessing Model Performance
To understand how your model is doing, focus on these key metrics:
| Metric | Description |
|---|---|
| Accuracy | Overall percentage of correct predictions |
| Precision | Percentage of predicted positives that are correct |
| Recall | Percentage of actual positives identified |
| F1-score | Balance between precision and recall |
Here’s how you can calculate these metrics using scikit-learn:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuracy = accuracy_score(y_test, predictions)
precision = precision_score(y_test, predictions)
recall = recall_score(y_test, predictions)
f1 = f1_score(y_test, predictions)
Adjusting Model Parameters
Fine-tuning your model’s parameters can significantly improve its performance. One effective way to do this is through hyperparameter tuning. If you’re just starting, focus on a smaller set of parameters to keep things simple. With scikit-learn, you can use GridSearchCV to automate this process:
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
Solving Common Problems
You might face two major issues while evaluating your model:
Overfitting:
- The model performs well on training data but poorly on test data.
- To address this, you can:
- Simplify the model using regularization.
- Stop training when validation performance starts to drop.
- Increase the size of your dataset.
Underfitting:
- The model struggles with both training and test data.
- To fix this, try:
- Adding more meaningful features.
- Using a more complex model.
- Training the model for a longer period.
"Using early stopping in a neural network can prevent overfitting by stopping the training process when the model's performance on the validation set starts to degrade." [1]
You can also test the reliability of your model with cross-validation. This method evaluates the model's performance across different data splits:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5)
Conclusion: Next Steps in Your Machine Learning Journey
Key Points to Keep in Mind
Building a solid understanding of the basics, like model metrics and tuning, is crucial for tackling more complex tasks. Python's ecosystem - especially libraries like scikit-learn - offers the tools you need for hands-on learning. Revisit key ideas such as underfitting, overfitting, and parameter tuning to sharpen your skills further.
Diving Into Advanced Topics
Once you're comfortable with the fundamentals, it's time to step into more advanced areas. Start with small, manageable projects to apply and expand your knowledge:
- Deep Learning: Experiment with TensorFlow, starting with image classification tasks.
- Natural Language Processing: Use scikit-learn for text classification projects.
- Computer Vision: Try basic image recognition using OpenCV.
Resources to Keep Learning
Here are some excellent resources to deepen your understanding and gain practical experience:
Recommended Resources:
- Books: Python Machine Learning by Sebastian Raschka is a great place to start.
- Courses: Check out Coursera's Machine Learning Specialization for structured learning.
- Practice: Participate in Kaggle competitions to tackle real-world problems.
Engage with the community on platforms like Stack Overflow or Reddit’s r/MachineLearning to stay updated and seek advice when you hit roadblocks.
{kind=link}